
快速导航
- 操作redis pipeline方式、压缩script方式 基本方式我删除了,太入门没啥用
- 操作mysql 加入了防止sql注入
- 操作json
- 优化篇 统一加载各个模块,开启开发模式(生产环境禁用!)
- lua执行时间
当前的操作,我尽可能优化了,如果真实情况使用,还是得需要上网找性能优化,方可高性能使用!
OpenResty 本质是对Nginx的增强,本文实践是通过http请求进来,我们讲请求交由lua处理,通过lua直接处理,避免我们java中tomcat并发能力差的问题!
我们先配置redis.conf 好请求路径,只要访问ip:9000/abc 就触发lua脚本了
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
# 加载lua模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# 加载c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
server {
listen 9000;
location / {
default_type text/html;
content_by_lua '
ngx.say("<p>Hello, World! second test!</p>")
';
}
location /abc {
# default_type text/html;
default_type application/json;
content_by_lua_file lua/a.lua;
}
}
}
创建lua/a.lua文件
lua操作Redis
pipeline即管道,可以理解为把多个命令打包然后一起发送;MTU(Maxitum Transmission Unit 最大传输单元)为二层包大小,一般为1500字节;而MSS(Maximum Segment Size 最大报文分段大小)为四层包大小,其一般是1500-20(IP报头)-20(TCP报头)=1460字节;因此假设我们执行的多个Redis命令能在一个报文中传输的话,可以减少网络往返来提高速度。因此可以根据实际情况来选择走pipeline模式将多个命令打包到一个报文发送然后接受响应,而Redis协议也能很简单的识别和解决粘包。
redis优化:pipeline合并发送redis命令
编辑a.lua 文件
-- 设置keepalive
local function close_redis( red )
if not red then
return
end
-- 释放连接(连接池实现)
local pool_max_idle_time = 10000 -- 连接池空闲时间(毫秒) 默认是60秒
local pool_size = 100 -- 连接池大小 默认是30个
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.say("set keepalive error : ", err)
else
ngx.log(ngx.ERR,"放入Redis连接池失败",err) -- 可以在nginx的error.log文件查看
end
end
-- 引入redis模块
local redis=require 'resty.redis'
-- 创建redis连接对象对象
local redisObj=redis:new()
-- 设置redis超时时间
local connectTimeout = 1000;
local requestTimeout = 1000;
local responseTimeout = 1000;
redisObj:set_timeout(connectTimeout, requestTimeout, responseTimeout)
-- 设置redis连接信息
local ok,err=redisObj:connect('192.168.31.204',6379)
-- 设置redis连接密码才可用
redisObj:auth('123456')
-- 判断是否连接redis成功
if not ok then
ngx.say('连接Redis失败:',err)
return
else
ngx.say('连接Redis成功:',ok)
end
-- 现在没开启pipeline,可以读取数据
local res,err=redisObj:get('username')
ngx.say('没开启pipeline从redis读取到的数据是:',res)
-- 开启init_pipeline 当你使用pipelineredis中间的命令,将不会去执行!最终统一返回在respTable,我们在这里拿数据处理即可!
redisObj:init_pipeline()
-- 存入数据 没开启pipeline这样使用 ok,err=redisObj:set('username','zhangsan')
redisObj:set('username','zhangsan')
-- 从redis中获取数据,现在是去不到的,必须等pipeline提交后才能获取!
local res,err=redisObj:get('username')
ngx.say('开启pipeline后从redis读取到的数据是:',res)
-- 提交
local respTable, err = redisObj:commit_pipeline()
-- 得到数据为空处理
if respTable == ngx.null then
respTable = {}
end
-- 结果是按照执行顺序返回的一个table
for i, v in ipairs(respTable) do
ngx.say("msg : ", v, "<br/>")
end
-- 关闭Redis连接
close_redes(redisObj)
ngx.say('redis操作完成,bye~')
测试 访问ip:9000/abc

完成对redis的操作了!
上述案例pipeline的形式是无法实现redis命令a结果作为redis命令b参数去使用的,也就是pipeline只适合多条命令互不影响的前提使用的。如果我们多条命令相互需要,我们可以想一下redis支持lua操作吧,我们一条命令,执行一个lua文件,这个lua文件直接操作多条redis命令不就行了嘛!本质就是通过openresty调用lua操作redis时,让redis自己执行lua!
Redis与脚本相关的命令如下
- EVAL - EVALSHA - SCRIPT EXISTS - SCRIPT FLUSH - SCRIPT KILL - SCRIPT LOAD
我们就可以通过redis操作lua的案例来实现我们的自己的功能!
我们先学一下eval 命令 eval "lua script" keynumbers ...
我们脚本要执行可传递参数,参数分为KEYS、ARGV两种类型,我个人认为没啥区别
命令分为3部分,lua script、key的数量、可变参数
key的数量含义是:key是几,那就代表可变参数前几个就是从KEYS[]取出来,其他可以作为ARGV[]取
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
我们可以看到上述命令讲述的是 返回传递的参数,以此顺序是 key第一个,key第二个,argv第一个,argv第二个
可想而知:如果要输出的结果就是 key1,key2,first,second
openresty也封装了redis执行lua的方法redis对象:eval('lua script',keysnumber,...)
redis优化:压缩script示例
我们通过定义 set name lisi后,去get name,如果value等于lisi,就执行set age 10
这里没用到连接池,真实环境自己从本文上面一个案例提取
-- 引入redis模块
local redis=require 'resty.redis'
-- 创建redis连接对象对象
local redisObj=redis:new()
-- 设置redis超时时间为1s
redisObj:set_timeout(1000)
-- 设置redis连接信息
local ok,err=redisObj:connect('192.168.31.204',6379)
-- 设置redis连接密码才可用
redisObj:auth('123456')
-- 判断是否连接redis成功
if not ok then
ngx.say('连接Redis失败:',err)
return
else
ngx.say('连接Redis成功:',ok)
end
-- 定义年龄
local age = 10
-- 注意在 Redis 执行脚本的时候,从 KEYS/ARGV 取出来的值类型为 string
local res, err = redisObj:eval([[
redis.call('set', 'name', 'lisi')
local nameRes = redis.call('get','name')
if nameRes ~= nil and nameRes == 'lisi' then
return redis.call('set','age',ARGV[1])
else
return 'name值不对!'
end
]], 0, age,age)
-- this 0 is key 0 (if 0 changes to 1,it means the first arguments as KEYS),others as ARGV arguments
-- redis:eval( command,keysnumber ...)
if not err then
ngx.say('redis设置成功了:',res)
else
ngx.say('redis has an error when lua is running',err)
end
-- 关闭redis
redisObj:close()
操作mysql
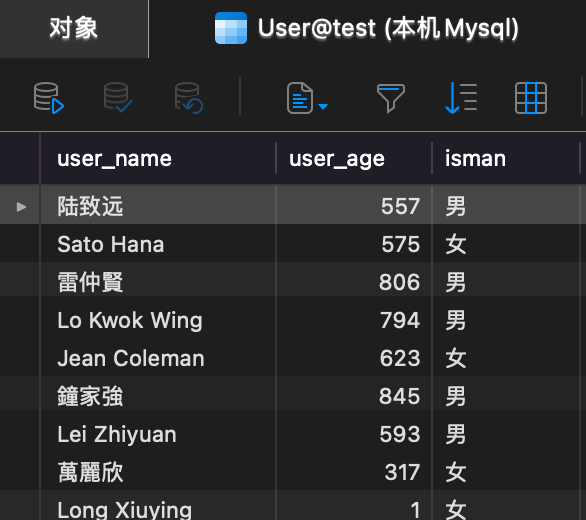
当前DB格式
修改a.lua文件
科普一下lua [[ ]] 是多行字符,字符串是"",多行就是[[ ]]
-- 引入Lua Mysql模块
local mysqL=require("resty.mysql")
-- 创建DB对象
local db=mysqL:new()
local ok,err=db:connect{
host="192.168.31.204",
port=3306,
user='root',
password='740969606',
database='test'
}
-- 设置DB超时时间,避免长时间阻塞
db:set_timeout(1000)
local name = "陆致远"
local badName = [[陆志远';drop table User;--]]
-- 这一行是模拟执行sql注入的,使用前请务必备份数据表
-- db:send_query(string.format([[select * from User where user_name = '%s']],badName))
-- 设定sql,同时调用ndk.set_var.set_quote_sql_str对特殊符号进行校验防止sql注入
db:send_query(string.format([[select * from User where user_name = %s limit 1]] , ndk.set_var.set_quote_sql_str(name)));
-- 读取数据
local res,err,errcode,sqlstate=db:read_result()
if not res then
ngx.say("bad result: ", err, ": ", errno, ": ", sqlstate, ".")
return
else
-- 关闭sqlSession
db:close()
-- 数据存储在res数组中 第一行数据就是res[1],字段是user_name 使用就是res[1].user_name
if res[1] ~= nil then
ngx.say('姓名:'..res[1].user_name..' ,学生年龄:'..res[1].user_age)
else
ngx.say("no res!")
end
end
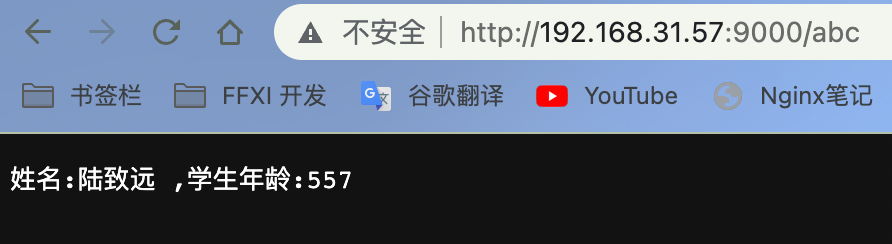
完成对Mysql的操作了
引入Cjson处理
编写a.lua文件
-- 引入lua模块
local myjson = require("cjson")
-- 定义数组,下一步将转为json
local dbRes = {"1","2","3"}
-- 将数组转为json
local returnjson = myjson.encode(dbRes) -- 数据转为json
local returnjson = myjson.decode(dbRes) -- json转为数据
-- 返回
ngx.say(returnjson)
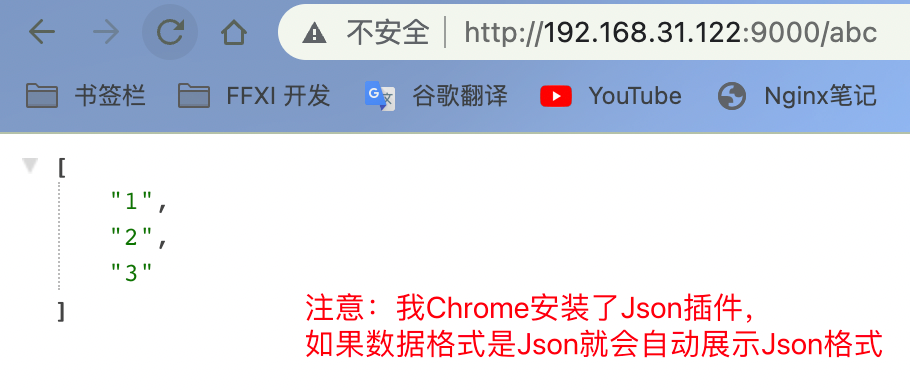
完成对json的处理了!
优化篇
每个lua执行时,都自己加载了各种模块,我们可以提前统一加载
在http块下面添加
# 在这里配置,这样当前http块内需要用到cjson模块时,都不需要独自加载了
init_by_lua_block{
cjson=require 'cjson'
}
在每个server下添加,off可以免重启
# 开发调试的时候使用off, 线上运行时设置为on。开发不用重启lua了,第一次识别此配置还是得重启
lua_code_cache off;
# 重启后会提示:nginx: [alert] lua_code_cache is off; this will hurt performance in /www/conf/nginx.conf:31 就是说off会影响性能!
示例
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
# 加载lua模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# 加载c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
# 在这里配置,这样当前http块内需要用到cjson模块时,都不需要独自加载了
init_by_lua_block{
-- 注意,这里面是lua语法,注释是两个杠 不是井号
cjson=require 'cjson';
-- mysql=require("resty.mysql");
-- redis=require 'resty.redis';
}
server {
listen 9000;
location / {
default_type text/html;
content_by_lua '
ngx.say("<p>Hello, World! second test!</p>")
';
}
location /abc {
lua_code_cache off;
# default_type text/html;
default_type application/json;
content_by_lua_file lua/a.lua;
}
}
}
测试一下json吧 我们修改a.json文件
-- 引入json我注释了,我们全局统一引入起的名字叫cjson,我们下文还是得依旧遵循cjson去使用
-- local cjson = require("cjson")
-- 定义数组,下一步将转为json
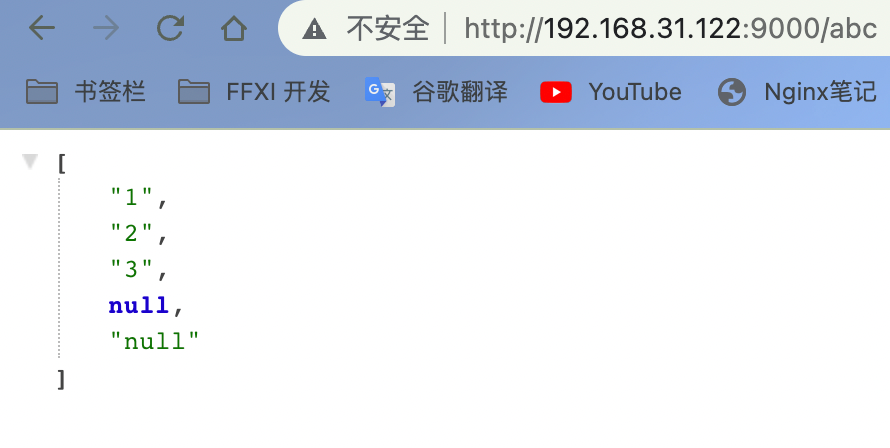
local dbRes = {"1","2","3",nil,"null"}
-- 将数组转为json
local returnjson = cjson.encode(dbRes)
-- 返回
ngx.say(returnjson)
本文基本就结束了,如果需要具体通过http请求形式,请参考本博客:https://www.zanglikun.com/12845.html
获取Lua 执行时间
local start_time = ngx.now()
-- 这里放入要执行的代码
ngx.say("time used:", ngx.now() - start_time)
-- 这是请求被nginx处理到lua执行结束的时间,更加准确!
ngx.say("time used:", ngx.now() - ngx.req.start_time()
ngx.say()与ngx.print() 都是输出,但是say会换行,print更适合优化文件碎片传输,因为没有换行,保证流传输正确性!
上述文章均是作者实际操作后产出。烦请各位,请勿直接盗用!转载记得标注原文链接:www.zanglikun.com
第三方平台不会及时更新本文最新内容。如果发现本文资料不全,可访问本人的Java博客搜索:标题关键字。以获取最新全部资料 ❤